ESXi storage connection problems after installing a new array
I was troubleshooting storage related problems at a customer site for some time. We run into massive ESXi storage connection problems after installing a new array. Interestingly enough problems occurred on already existing storage a few hours after new array was installed.
Because searching for root cause took some time, I thought it is worth to share.
Starting Situation
The customer was running HPE 3PAR 7200 arrays without any problems. He ordered new HPE Primeras to migrate VMs there. We implemented the new arrays and connected them to the existing Fibre Channel (FC) switches, did the zoning and create ESXi hosts in Primera configuration.
Environment
- vCenter and ESXi hosts were running 6.7 U3.
- Storage was connected through FC using HPE branded Qlogic adapter (SN1000Q and SN1100Q). ESXi was running driver
qlnativefc. - ESXi hosts were running on HPE ProLiant hosts with quite current Support Pack Proliant (SPP).
- Storage arrays:
- HPE 3PAR 7200 (existing one)
- HPE Primera A630 (new one)
Symptoms
The following symptoms were seen a few hours after zoning on FC switches were made and Primera host definitions for ESXi hosts – using VMware persona – were created. So hours after ESXi hosts saw the new arrays.
- Error counter
- Vast number of HBA errors in ESXi hosts. See my script here for watching these errors.
- HBA errors appeared on both fabrics!
- No errors appeared on any FC switch port. You can check by running
porterrshowon Brocade switches. - No errors appeared on any HPE 3PAR or Primera FC port. Can be checked by running
showportlesb both 0:0:1on 3PAR/Primera array – where0:0:1can be replaced by any FC port.
- Error messages
- Tons of errors in
vmkernel.loglikeqlnativefc: vmhba0(37:0.0): qlnativefcUnregSess sess 0x430f3870d390 for deletion nn:nn:nn:nn:nn:nn:nn:nnWARNING: NMP: nmp_DeviceRequestFastDeviceProbe:237: NMP device "naa.nnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnn" state in doubt; requested fast path state update…ScsiDeviceIO: 3414: Cmd(0x45a3d0af5440) 0x28, CmdSN 0x8000006f from world 2143802 to dev "naa.nnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnn" failed H:0x2 D:0x0 P:0x0 Invalid sense data: 0x20 0x44 0x3a.
- Errors in
vmkernel.logwere often related to a specific volume. On another host errors were related to a different volume. - Errors in
vobd.loglike[esx.problem.storage.redundancy.degraded] Path redundancy to storage device naa.nnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnndegraded. Path vmhba0:C0:T2:L2 is down. Affected datastores: "datastore_name".[vob.scsi.scsipath.pathstate.standby] scsiPath vmhba0:C0:T2:L2 changed state from dead[esx.clear.storage.redundancy.restored] Path redundancy to storage device naa.nnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnnn (Datastores: "datastore_name") restored. Path vmhba0:C0:T2:L2 is active again.
- Tons of errors in
- Performance
- On hosts with HBA errors counters and log messages performance was massively reduced.
- Management
- Hosts with errors could have been disconnected from vCenter.
Root cause
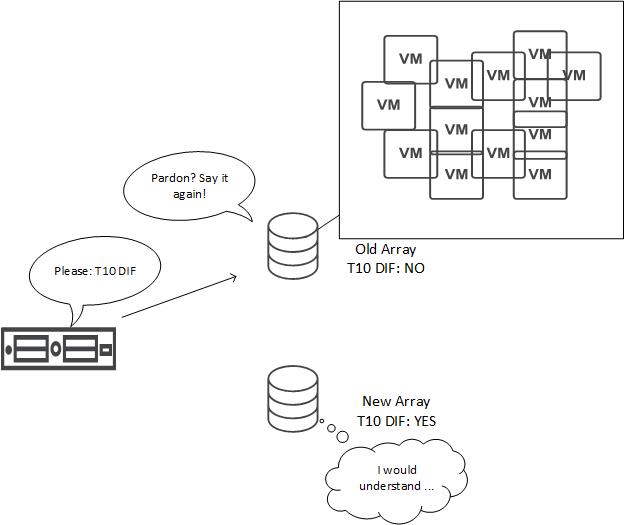
It turned out, the problem is related to a 3PAR/Primera feature named Persistent Checksum (read about this feature in HPE 3PAR Architecture technical white paper on Page 21). This feature is based on SCSI T10 DIF and available for 3PAR 8k, 20k and Primera arrays. It is enabled by default.
Root cause was not Persistent Checksum itself, it was a bug in HBA driver qlnativefc. This bug caused the HBA to send IOs with T10 DIF data to arrays that does not support T10 DIF – in my case: 3PAR 7200. Therefore IOs have to be re-sent. And this happens in a large scale.
Solution
There are a few solutions to this issue:
Fast workaround: disable port
When you disable the FC switch port of the host HBA port that counts most errors, problem is stopping immediately. To disable port n on a Brocade switch, run: portdisable n.
Disable T10 DIF on ESXi host
T10 DIF feature can be disabled on a host. Setting is on HBA driver layer, so it is global for the host. To disable T10 DIF, run one of the following commands and reboot the host.
esxcli system module parameters set -p ql2xt10difvendor=0 -m qlnativefcesxcfg-module -s 'ql2xt10difvendor=0' qlnativefc
To check current setting, run one of these commands:
esxcli system module parameters list -m qlnativefc | grep t10difesxcfg-module -g qlnativefc
Update driver
According to HPE Support and advisory, these driver versions are affected:
- ESXi 6.7
- 3.1.29.0
- 3.1.31.0
- ESXi 6.5
- 2.1.94.0
- 2.1.96.0
To check used driver version, run this command: esxcli storage san fc list
Notes
- See HPE advisory about this issue here for more information.
- We did see this behavior just with SN1000Q HBAs.
- In my scenario, we updated HBA firmware and driver to 3.1.36.0 and kept T10 DIF enabled. This resolved our problems.
- This problem is not related to any storage vendor! It is a problem of the HBA driver, not the array!
- We did not try, but disabling Persistent Checksum at Primera Virtual Volume layer will not work. This because we did not export any volume and suffered from this anyway.
- Here is another link to read more about T10 DIF in 3PAR arrays.
Veeam Vanguard

Veeam Legend

VMware vExpert
